go语言现在是越来越火了,使用过程中发现error的用法和java比起来太不一样了,有人很讨厌到处都要判断err != nil,也有人喜欢这种即时处理的方式,本文简单分析下error的优劣,以及最佳使用方式

druid主要功能就是连接池,池化技术很常见了,druid能保证高性能,肯定也有过人之处,尤其是其检测能力也很突出,connection连接池的初始化、创建、回收、收缩、获取,都是关键点。

SQL Parser是Druid的一个重要组成部分,Druid内置使用SQL Parser来实现防御SQL注入(WallFilter)、合并统计没有参数化的SQL(StatFilter的mergeSql)、SQL格式化、分库分表。使用sqlParse可以做很多个性化的事情,比如做一套sql校验的东西,给指定的sql再添加查询条件,或者添加连表查询,再比如也可以做数据的血缘分析等。


最近看到很多文章讲解mysql的隔离级别,以及幻读,但是很多文章写的感觉不是很对,对幻读的理解以及如何解决的说的都不是很清楚,那么最好的理解就是实战下看看。

通过学习druid连接池,尝试自己写一个数据库连接池

连接是整个druid核心的东西,怎么去维护,怎么保证高效的创建,不会多创建,也不会导致池中可用连接为0呢,本文具体看下连接的创建,维护,销毁一整个生命周期,以及锁的玩法。

这周就要开始druid的连接池部分的源码阅读了,看之前还是先直观的看下整体的功能,以及特点。

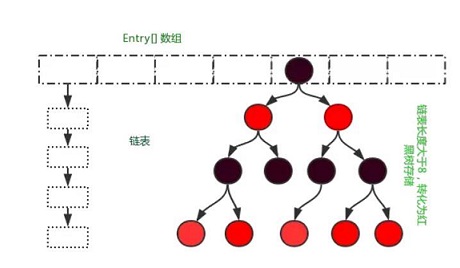
水一篇,一天一篇druid的,坑不住了,druid中的ast语法树解析以及遍历,也用到了一些算法的思想,都很精髓,其中就有dfs的遍历,不免想到二叉树的玩法,随便复习下二叉树的各种算法。

sqlparse通过前几篇的博客学习,知道它其实是一个单独的功能,可以独立使用的,那么druid是怎么使用它的呢,用在哪些方面呢,我们再来研究下。

前几篇博客学习了parser的基本用法,原理,以及通过阅读源码知道了如何将一条sql,解析为一颗语法树,那么语法树已经构建好了,怎么访问呢,如何才能获取我想要的结构呢?这篇我们看下visitor的实现

上篇学习了sqlparser的功能,大致原理,使用方向,以及demo,学习就要知其然,知其所以然,这篇博客学习下druid-sqlparser的源码,看下到底是怎么实现的

位运算性能很高,但是一般我们也就在做算法的时候,偶尔用用,实际项目中很少用到,今天就介绍下如何用位运算让一个值表示多个状态。

MapStruct是一个代码生成器,它基于约定优于配置的方法极大地简化了Java bean类型之间映射的实现,简单易用,高性能,没有理由不用它,已得到广泛应用。

每个做技术的都有大厂梦,但是大厂也不是那么好进的,尤其对于学历不是那么高的,经过前后近半年的准备,陆续也拿到了一些offer,写这篇面经既是对自己的总结,也为有需要的提供点自己的经验吧

学习了消息队列基础,消息队列协议,常见的MQ,Kafka的详解,以及如何自定义一个MQ

分布式缓存知识详解 原创
分布式缓存详解,深入理解缓存数据特点,缓存策略,常见的缓存问题,redis详解,redis的高可用,以及内存网格 - Hazelcast